AI Performance Myths: Do IOPS Actually Matter?
NeutralArtificial Intelligence
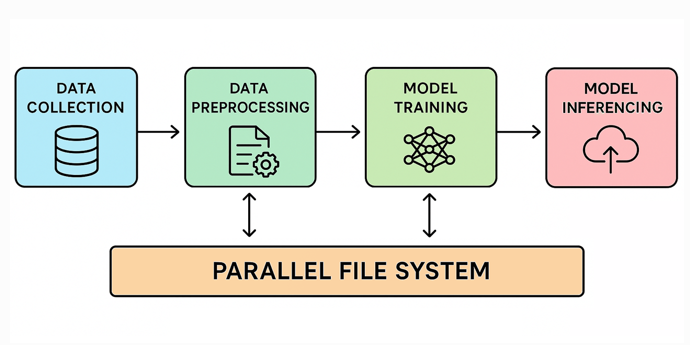
In the context of the growing importance of artificial intelligence and machine learning, the article by Petros Koutoupis highlights the role of input/output operations per second (IOPS) as a key performance metric in assessing data storage solutions. While IOPS is widely recognized, the piece argues that organizations must look beyond this single metric to fully leverage the transformative potential of AI. This perspective aligns with ongoing discussions in the tech community about the need for comprehensive storage strategies that support high-performance computing. As organizations increasingly rely on AI for innovation, understanding the nuances of data storage becomes critical for maximizing efficiency and effectiveness.
— via World Pulse Now AI Editorial System
