Kimi K2 Thinking Crushes GPT-5, Claude 4.5 Sonnet in Key Benchmarks
PositiveArtificial Intelligence

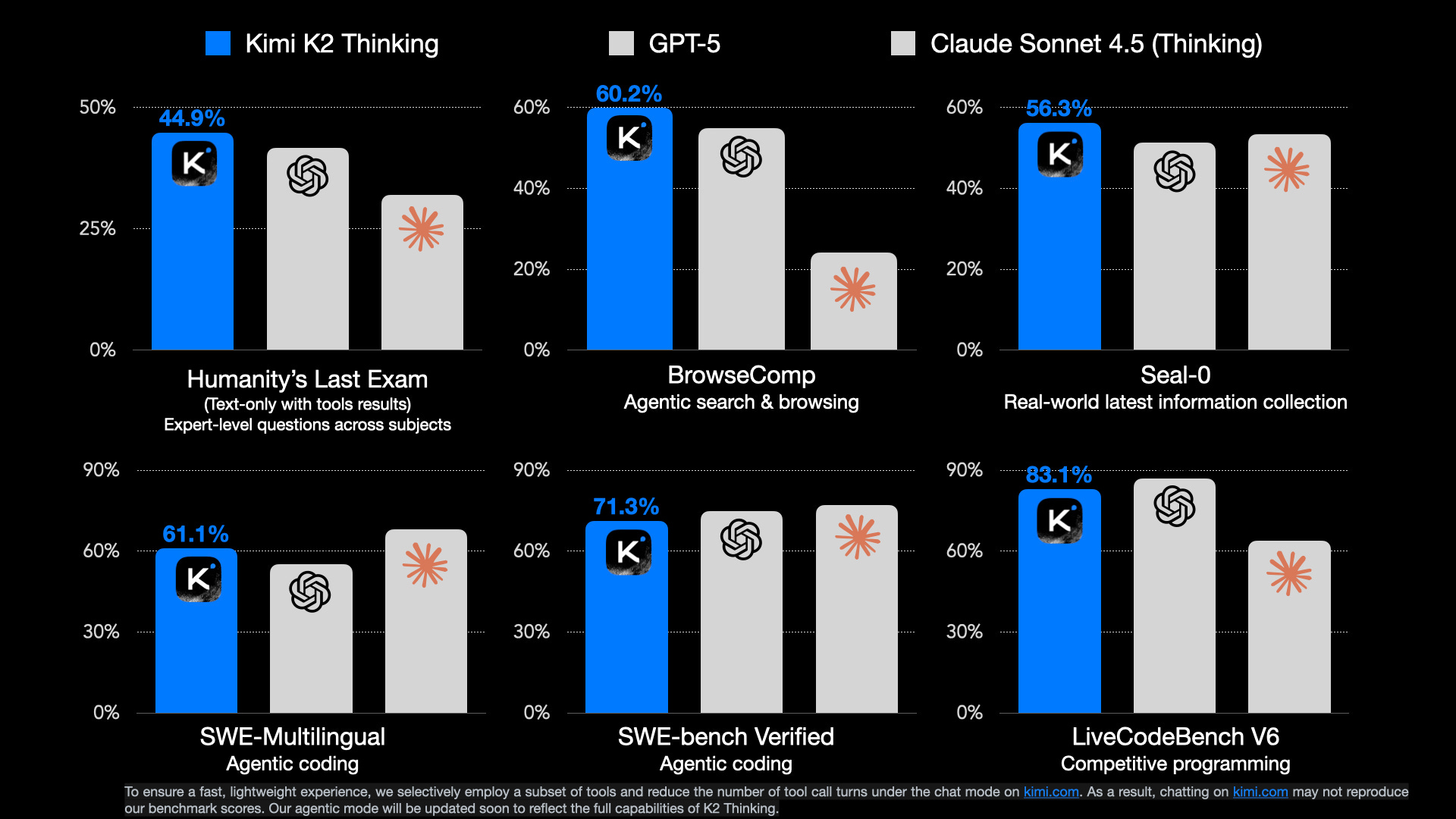
Kimi K2 Thinking Crushes GPT-5, Claude 4.5 Sonnet in Key Benchmarks
In a significant development in the AI landscape, Kimi K2 has outperformed both GPT-5 and Claude 4.5 in key benchmarks, showcasing its advanced capabilities. This achievement is crucial as it highlights the rapid evolution of artificial intelligence technologies and the competitive edge that Kimi K2 brings to the table. As companies and developers look for the best AI solutions, Kimi K2's performance could influence future investments and innovations in the tech industry.
— via World Pulse Now AI Editorial System