Blu-WERP (Web Extraction and Refinement Pipeline): A Scalable Pipeline for Preprocessing Large Language Model Datasets
PositiveArtificial Intelligence
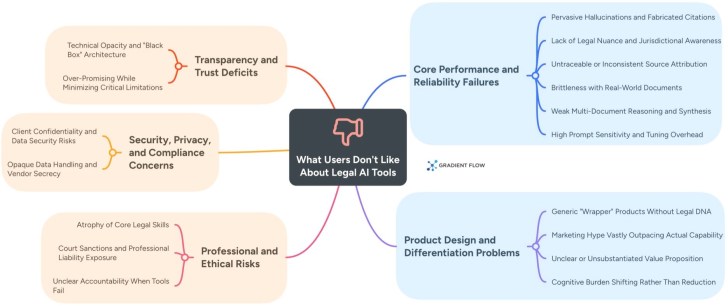
- The introduction of Blu-WERP, a new data preprocessing pipeline, aims to enhance the quality of training data for large language models (LLMs) by effectively filtering noise from web-scale datasets, particularly Common Crawl WARC files. This pipeline has demonstrated superior performance compared to existing methods like DCLM across various model scales and evaluation benchmarks.
- The significance of Blu-WERP lies in its ability to optimize training data quality, which is crucial for the performance of LLMs. By implementing advanced filtering and quality assessment mechanisms, Blu-WERP addresses a key challenge in the field of natural language processing, potentially leading to more accurate and reliable AI applications.
- This development reflects a broader trend in AI towards improving data quality and model efficiency. As the demand for high-performing language models increases, techniques such as quantization and model compression are becoming essential. The focus on refining data extraction methods, as seen with Blu-WERP and similar initiatives, highlights the ongoing efforts to enhance AI capabilities while managing computational resources effectively.
— via World Pulse Now AI Editorial System